
Library of Congress Format Descriptions Visualization
04 Dec 2023Spoiler alert: If you want to browse what I came up with, you can check it out here: https://lc-sdf-data-exploration.vercel.app/
Readers of this blog will know that I’ve been working through researching 39 formats for the Library of Congress Sustainability of Digital Formats site because I’ve been blogging about it weekly since August (and that series will continue until end of next May).
I had a bit of holiday downtime, so I was thinking about the questions I had about the collection as a whole instead of individual points of data, and wondering how I could go about answering some of those questions. To do this, I had to transform the individual files into something I could analyze, something like a database.
For a moment I thought about working with potential intermediaries: XML to JSON to CSV to Database? But I jumped straight from XML to Database.
Here are some (loosely structured) notes on my thinking process:
My mission:
Current format: ~500 XMLs
Target format: sqlite database
Data mapping
First, data mapping. What does the structure of the XML look like? I have been working with an XSD, but it’s a bit verbose and contains more information than what I need.
XML: Is there a way to extract elements in an easier-to-view mode?
Yes, xmlstarlet el [your-xml.xml]
There are a lot of repeating fields though, so let’s sort that out, uniquely:
xmlstarlet el [your-xml.xml] | sort | uniq -u
Now there’s still a lot of stuff to go through, but it’s more manageable than doing it one-by-one. Below are the properties with the namespaces and top-level element removed, for ease of reading.
# Properties
properties/draftStatus
properties/formatCategories/category
properties/gdfrComposition
properties/gdfrConstraint
properties/gdfrForm
properties/gdfrGenreSelection/gdfrGenre
properties/updates/date
# Identification and Description
identificationAndDescription/description
identificationAndDescription/fullName
identificationAndDescription/keywords
identificationAndDescription/productionPhase
identificationAndDescription/relationships
identificationAndDescription/shortDescription
# File Type Signifiers
fileTypeSignifiers/signifiersGroup/filenameExtension/sigValues
fileTypeSignifiers/signifiersGroup/filenameExtension/sigValues/sigValue
fileTypeSignifiers/signifiersGroup/magicNumbers/note
fileTypeSignifiers/signifiersGroup/magicNumbers/sigValues
fileTypeSignifiers/signifiersGroup/other/values/sigValueNA
# LC Local Use
localUse/experience
localUse/preference
# Sustainability factors
sustainabilityFactors/adoption
sustainabilityFactors/disclosure
sustainabilityFactors/documentation
sustainabilityFactors/externalDependencies
sustainabilityFactors/licensingAndPatents
sustainabilityFactors/selfDocumentation
sustainabilityFactors/techProtection
sustainabilityFactors/transparency
# Q & F (These will need to be handled per-category, here's an example)
## soundQF
qualityAndFunctionalityFactors/soundQF/beyondSound
qualityAndFunctionalityFactors/soundQF/channels
qualityAndFunctionalityFactors/soundQF/fidelity
qualityAndFunctionalityFactors/soundQF/normalSound
qualityAndFunctionalityFactors/soundQF/samples
# Notes
notes/general
notes/history
# Format specifications / references
formatSpecifications/urls
usefulReferences/urls
Now, some of these are easy key-values and others are repeating fields of indeterminate size, so we need to handle those through multiple tables (something harder to hold in one’s head, as it were). Some are multiples, but can be concatenated and mapped to a single string field. Also, not covered here but a problem for the near-term future is that some fields also have a lot of <p> and <a> tags, along with this XML’s specific <fddLink>.
Here I am going to add types to give me an idea for whether I’ll need to break a field out into a related table or not.
# Properties
properties/draftStatus : string
properties/formatCategories/category : string (concat)
properties/gdfrComposition : string
properties/gdfrConstraint : string
properties/gdfrBasis : string
properties/gdfrForm : string
properties/gdfrGenreSelection/gdfrGenre : string (concat)
properties/updates/date : string
# Identification and Description
identificationAndDescription/description : string
identificationAndDescription/fullName : string
identificationAndDescription/keywords : string
identificationAndDescription/productionPhase : string
identificationAndDescription/relationships : TABLE
identificationAndDescription/shortDescription : string
# File Type Signifiers
## (there are more here than what is listed)
## Could consider a concat strategy for this entire section
## it'll be complicated either way
fileTypeSignifiers/signifiersGroup/filenameExtension/sigValues/sigValue
fileTypeSignifiers/signifiersGroup/magicNumbers/note
fileTypeSignifiers/signifiersGroup/magicNumbers/sigValues
fileTypeSignifiers/signifiersGroup/other/values/sigValueNA
# LC Local Use
localUse/experience : string
localUse/preference : string
# Sustainability factors
sustainabilityFactors/adoption : string
sustainabilityFactors/disclosure : string
sustainabilityFactors/documentation : string
sustainabilityFactors/externalDependencies : string
sustainabilityFactors/licensingAndPatents : string
sustainabilityFactors/selfDocumentation : string
sustainabilityFactors/techProtection : string
sustainabilityFactors/transparency : string
# Q & F (These will need to be handled per-category)
## Is this better as a separate table?
## soundQF
qualityAndFunctionalityFactors/soundQF/beyondSound : string
qualityAndFunctionalityFactors/soundQF/channels : string
qualityAndFunctionalityFactors/soundQF/fidelity : string
qualityAndFunctionalityFactors/soundQF/normalSound : string
qualityAndFunctionalityFactors/soundQF/samples : string
# Notes
notes/general : string
notes/history : string
# Format specifications / references
formatSpecifications/urls : TABLE
usefulReferences/urls : TABLE (can be same table as above)
So that’s three tables total:
- main table
- relationships table: FDD ID, Related FDD ID (id, shortName, titleName), relationship type, note
- references table: FDD ID, Reference (link, tag, comment). (which can’t be called ‘references’, a SQL keyword, so I called it citations, instead)
Script writing
With this, I wrote a script to parse the XML and map the values into a SQL database (storing as a sqlite.db file). This lets me explore the data as a collection (and brush up on my very neglected SQL skills).
I did end up severely smushing two major categories, as implied about: File Type Signatures and Quality & Functionality. These are two important sections, but more on the individual scale. It was just a lot harder to think about “flattening” them into rows, especially when the Q&F fields change based on the category of format and the file type signatures are “zero or more, repeating” so I can’t just match and fill a column with the exact result, if present. I mean, I could probably do a lot of that, but I chose not to do that at this time. Pulling out just the PRONOM and Wikidata (and again smushing together the multi-fields) is probably something I should consider next, because those are the most frequently used. And file extension. But in terms of assessing the collection as a whole, I think there’s value in determining which FDDs lack these fields, and that could still be done with some crafty SQL’ing.
SQL publishing
With this database, I wanted to set up and publish as a Datasette to make it easier to play around in.
This was surprisingly easy to do! It’s been a while since I’ve had literally any package/program just work right off the bat like this.
This is nice too because I am inexplicably unskilled at SQL, and having it visualized and with helper functions made it feel softer to me.
From there, I wanted to utilize the visualization features in Datasette and found this datasette-dashboards plug-in, which was also easy to add and customize the examples with my own SQL queries.
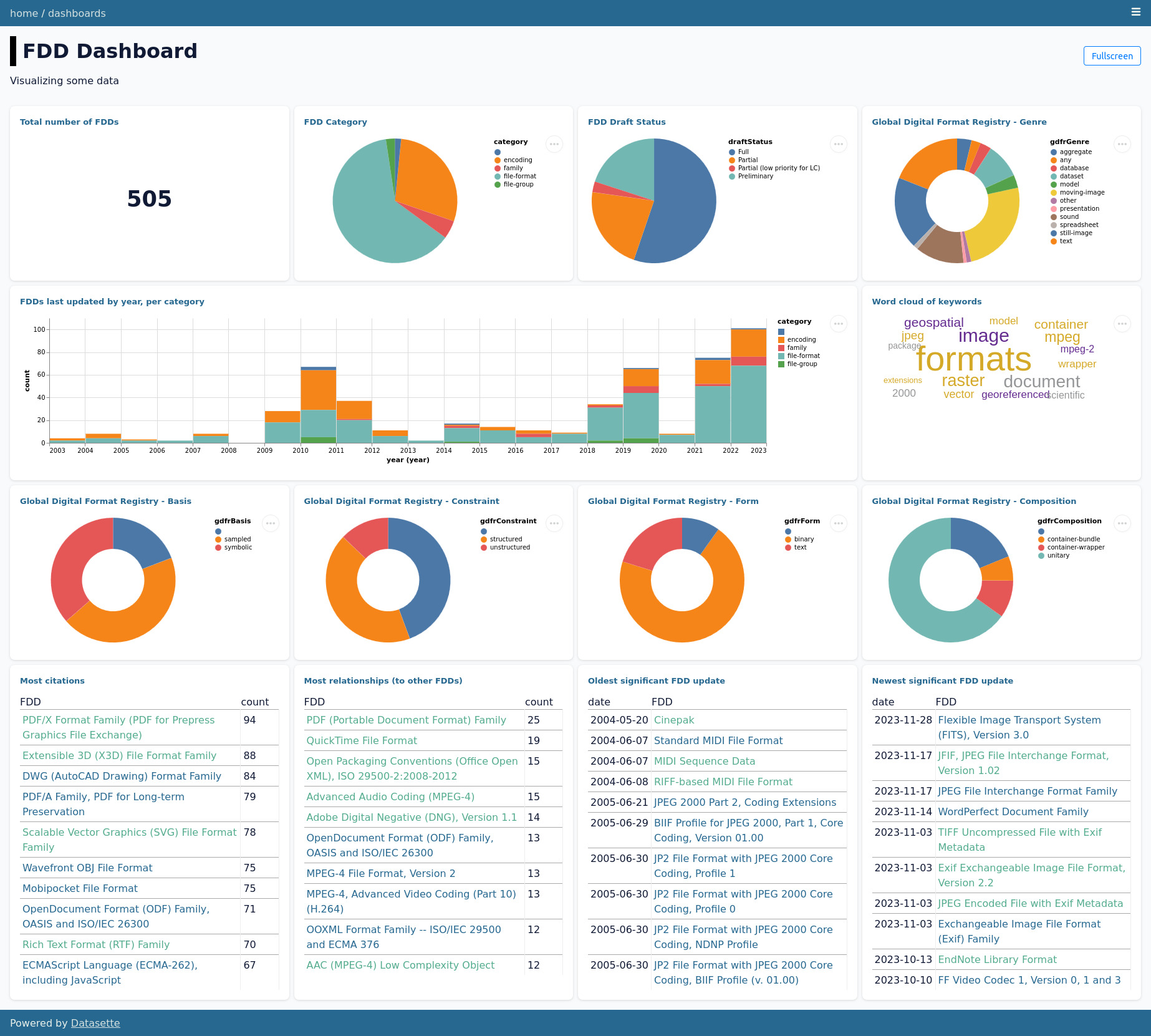
There were some data issues that I was able to clean up after building these dashboards, just small things mostly around me running the ‘relationships’ too many times, and not picking up all the citations because I was being too specific with the XPath.
App deploying
The last thing to do was deploy, which I did (as also linked at the top of this post).
Deploying should have been straightforward, but something truly weird happened. I chose fly.io to host the datasette, in part because my husband had been using it for some of his for-fun apps, and because datasette has a fly.io publishing plugin that I could install and make it easy. But weirdly, inexplicably, truly beyond my wildest imagination, despite never having used flyio on my computer before, it initially threw a bunch of errors, and then deployed to my husband’s account. I wasn’t logged into his account or any account at the time. What??????????????
Other than that bizarre and seemingly not-very-secure behavior, it did deploy properly after only two attempts (forgot to include an additional plugin’s path), and that was that!
Except it wasn’t just that! After that, it was working fine until it was not adhering to my config setting that enforced https, causing mixed content errors even though it was working fine before which caused me to eat an entire box of reese’s pieces out of frustration (away from the computer, watching Leave the World Behind, which I really liked)!!!!!
I moved over to Vercel, also using a datasette plug-in, and it was easy-breezy-lemon-squeezy: https://lc-sdf-data-exploration.vercel.app/
I’ll never use fly.io again, they are my new enemy, and my blood glucose has risen.
Next up
I started this project wanting to map out relationships specifically, and I didn’t really get around to doing that because it involved doing some additional boutique work instead of the work pushing puzzle pieces together to pull together some dashboards. I may return to that, because I’m still interested in understanding which FDDs relate to others, but I consider this project a good first step in shaping the data before dipping into d3.js. Especially because Datasette allows for easy conversion from database to JSON-structured data!